МОТП, Билеты (2009)
Материал из eSyr's wiki.
Часть 1 (Ветров)
Метод максимального правдоподобия. Его достоинства и недостатки.
Недостатки:
- нужно знать априорное распределение (с точностью до параметров) наблюдаемой величины
- хорошо применим при допущении, что
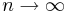 (асимптотически оптимален), что в реальности не так
(асимптотически оптимален), что в реальности не так
- проблема выбора структурных параметров, позволяющих избегать переобучения (проблема вообще всех методов машинного обучения)
- необходима регуляризация метода
Решение несовместных СЛАУ.
В статистике, машинном обучении и теории обратных задач под регуляризацией понимают добавление некоторой дополнительной информации к условию с целью решить некорректно поставленную задачу или предотвратить переобучение.
Несовместная СЛАУ -- система линейных уравнений, не имеющая ни одного решения.
Совместная СЛАУ -- система линейных уравнений, имеющая хотя бы одно решение.
Ридж-регуляризация (ридж-регрессия, регуляризация Тихонова) матрицы ATA -- матрица ATA + λI, где λ -- коэффициент регуляризации. Всегда невырождена при λ > 0
Нормальное псевдорешение СЛАУ Ax = b -- вектор x = (ATA + λI) − 1ATb
- всегда единственно
- при небольших λ определяет псевдорешение с наименьшей нормой
- любое псевдорешение имеет минимальную невязку
Задача восстановления линейной регрессии. Метод наименьших квадратов.
Задача регрессионного анализа (неформально).
Предположим имеется зависимость между неизвестной нам случайно величиной X (мы судим о ней по наблюдаемым признакам, т.е. по случайной выборке) и некоторой переменной (параметром) t.
Задача регрессионного анализа — определение наличия и характера (математического уравнения, описывающего зависимость) связи между переменными. В случае линейной регрессии, зависимость X от параметра t проявляется в изменении средних значений Y при изменении t (хотя при каждом фиксированном значении t величина X остается случайной величиной).
Искомая зависимость среднего значения X от значений Z обозначается через функцию f(t): E(X | Z = t) = f(t). Проводя серии экспериментов, требуется по значениям t1,...tn и X1,...,Xn оценить как можно точнее функцию f(t).
Однако, наиболее простой и изученной является линейная регрессия, в которой неизвестные настраиваемые параметры (wj) входят в решающее правило линейно с коэффициентами ψj(x): 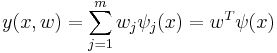
Пример (простой пример на пальцах): Linear Regression Example
 — функция потерь от ошибки. На пальцах: берем найденную путем регрессии функцию
— функция потерь от ошибки. На пальцах: берем найденную путем регрессии функцию  и сравниваем её выдачу на тех же наборах x, что и заданные результаты эксперимента t(x).
и сравниваем её выдачу на тех же наборах x, что и заданные результаты эксперимента t(x).
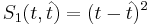
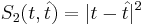
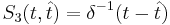
Основная задача — минимизировать эту функцию, что значит минимизировать 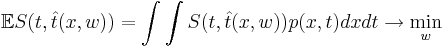
Метод наименьших квадратов — минимизация функции потери ошибки 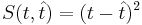
Особенности квадратичной функции потерь:
- Достоинтсва
- гладкая (непрерывная и дифференцируемая)
- решение может быть получено в явном виде
- Недостатки
- решение неустойчиво
- не применима к задачам классификации
Задача восстановления линейной регрессии. Вероятностная поставновка.
Представим регрессионную переменную как случайную величину с плотностью распределения p(t | x)
В большинстве случаев предполагается нормальное распределение относительно некоторой точки y(x) : 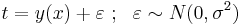
[?]: почему в лекциях (лекция 1, слайд 22): 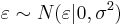 Как я понимаю
Как я понимаю 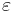 -- это произвольный параметр, мы просто предполагаем, что он распределен нормально.
-- это произвольный параметр, мы просто предполагаем, что он распределен нормально.
максимизируя правдоподобие получаем эквивалентность данного метода методу наименьших квадратов
Логистическая регрессия. Вероятностная постановка.
ЕМ-алгоритм для задачи разделения гауссовской смеси.
Основные правила работы с вероятностями. Условная независимость случайных величин.
Графические модели. Основные задачи, возникающие в анализе графических моделей.
Байесовские сети. Примеры.
Марковские сети. Примеры.
Скрытые марковские модели. Обучение СММ с учителем.
Алгоритм динамического программирования и его применение в скрытых марковских моделях.
ЕМ-алгоритм и его применение в скрытых марковских моделях.
Условная независимость в скрытых марковских моделях. Алгоритм «вперед-назад».
Метод релевантных векторов в задаче восстановления регрессии.
Метод релевантных векторов в задаче классификации.
Метод главных компонент.
Пусть имеется некоторая выборка 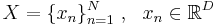 . Цель -- представить выборку в пространстве меньшей размерности d < D таким образом, чтобы в новом пространстве "схожие" объекты образовывали компактные области.
. Цель -- представить выборку в пространстве меньшей размерности d < D таким образом, чтобы в новом пространстве "схожие" объекты образовывали компактные области.
PCA (Principal Component Analysis) -- Метод главных компонент. Формулировки:
- проекция данных на гиперплоскость с наименьшей ошибкой проектирования
- поиск проекции на гиперплоскость с сохранением большей части дисперсии в данных
Вероятностная формулировка метода главных компонент.
ЕМ-алгоритм в методе главных компонент. Его преимущества.
Метод главных компонент. Схема автоматического выбора числа главных компонент.
Недостатки метода главных компонент. Метод независимых компонент.
Нелинейные методы уменьшения размерности. Локальное линейное погружение.
Нелинейные методы уменьшения размерности. Ассоциативные нейронные сети и GTM.
Часть 2 (Рудаков)
Объекты, признаки, логические признаки, простейшие логические решающие правила.
Признаки объектов:
- детерминированные;
- вероятностные;
- логические;
- структурные.
Детерминированные признаки – это признаки, принимающие конкретные числовые значения, которые могут быть рассмотрены как координаты точки, соответствующей данному объекту, в n-мерном пространстве признаков.
Вероятностные признаки – это признаки, случайные значения которых распределены по всем классам объектов, при этом решение о принадлежности распознаваемого объекта к тому или другому классу может приниматься только на основании конкретных значений признаков данного объекта, определенных в результате проведения соответствующих опытов. Признаки распознаваемых объектов следует рассматривать как вероятностные и в случае, если измерение их числовых значений производится с такими ошибками, что по результатам измерний невозможно с полной определенностью сказать, какое числовое значение данная величина приняла.
Логические признаки распознаваемых объектов можно рассматривать как элементарные высказывания, принимающие два значения истинности (истина – ложь) с полной определенностью. К логическим признакам относятся прежде всего признаки, не имеющие количественного выражения. Эти признаки представляют собой суждения качественного характера типа наличия или отсутствия некоторых свойств или некоторых элементов у распознаваемых объектов или явлений. В качестве логических признаков можно рассматривать, например, такие симптомы в медицинской диагностике, как боль в горле, кашель и т.д. К логическим можно отнести также признаки, у которых важна не величина признака у распознаваемого объекта, а лишь факт попадания или непопадания ее в заданный интервал. В пределах этих интервалов появление различных значений признаков у распознаваемых объектов предполагается равновероятным. На практике логические признаки подобного рода имеют место в таких ситуациях, когда либо ошибками измерений можно пренебречь, либо интервалы значений признаков выбраны таким образом, что ошибки измерений практически не оказывают влияния на достоверность принимаемых решений относительно попадания измеряемой величины в заданный интервал.
Остаток можно взять из файла lekcii_ama_zhuravlev.doc страница 17.
Проблемы формирования логических признаков. Оценки качества признаков и их совокупностей.
Пусть 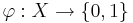 - некоторый предикат, определённый на множестве объектов X. Говорят, что предикат
- некоторый предикат, определённый на множестве объектов X. Говорят, что предикат 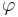 выделяет или покрывает (cover) объект x, если
выделяет или покрывает (cover) объект x, если
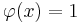 . Предикат называют закономерностью, если он выделяет достаточно много объектов какого-то одного класса c, и практически не выделяет объекты других классов.
. Предикат называют закономерностью, если он выделяет достаточно много объектов какого-то одного класса c, и практически не выделяет объекты других классов.
Пример: Решается вопрос о целесообразности хирургической операции. Закономерность: если возраст пациента выше 60 лет и ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода велик.
Всякая закономерность классифицирует лишь некоторую часть объектов. Объединив определённое количество закономерностей в композицию, можно получить алгоритм, способный классифицировать любые объекты. Логическими алгоритмами классификации будем называть композиции легко интерпретируемых закономерностей. При построении логических алгоритмов возникают три основных вопроса:
- Каков критерий информативности, позволяющий называть предикаты закономерностями?
- Как строить закономерности?
- Как строить алгоритмы классификации на основе закономерностей? Наиболее распространённые типы логических алгоритмов: Голосование правил (алгоритм Кора), Алгоритмы вычисления оценок.
Теперь поговорим об информативности (или качестве) признака.
Своими словами: предикат \varphi тем более информативен, чем больше он выделяет объектов "своего класса" 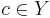 по сравнению с объектами всех остальных "чужих" классов. Свои объекты называют также позитивными (positive), а чужие негативными (negative). Введём следующие обозначения:
по сравнению с объектами всех остальных "чужих" классов. Свои объекты называют также позитивными (positive), а чужие негативными (negative). Введём следующие обозначения:
- Pc - число объектов класса c в выборке X
-
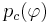 - из них число объектов, для которых выполняется условие ;
- из них число объектов, для которых выполняется условие ;
- Nc - число объектов всех остальных классов Y \ {c} в выборке X
-
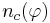 - из них число объектов, для которых выполняется условие
- из них число объектов, для которых выполняется условие
Введем ещё два обозначения:
-
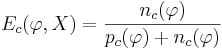 - доля негативных объектов среди всех выделяемых объектов (доля тех объектов, в которых наш логический предикат ошибся - причислил их к "своему" классу, хотя они туда и не относились)
- доля негативных объектов среди всех выделяемых объектов (доля тех объектов, в которых наш логический предикат ошибся - причислил их к "своему" классу, хотя они туда и не относились)
-
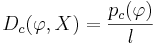 , где l есть это количество элементов в выборке X - это доля выделенных позитивных объектов.
, где l есть это количество элементов в выборке X - это доля выделенных позитивных объектов.
Существует несколько способов определения информативности: статическое определение, энтропийное. Также существует такое понятие как многоклассовая информативность, когда приходится оценивать информативность не только таких предикатов, которые отделяют один класс от остальных, но и таких, которые отделяют некоторую группу классов от остальных.
Методы голосования по конъюнкциям. Алгоритмы типа "Кора".
Для начала, поговорим об алгоритмах голосования. Пусть для каждого класса построено множество логических закономерностей (правил), специализирующихся на различении объектов данного класса:
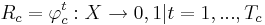 , где Tc - количество классов свойств.
, где Tc - количество классов свойств.
Считается, что если 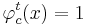 , то правило
, то правило 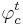 относит объект
относит объект 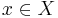 к классу c. Если же
к классу c. Если же 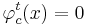 , то правило воздерживается от классификации объекта x.
, то правило воздерживается от классификации объекта x.
- Алгоритм простого голосования
- подсчитывает долю правил в наборах Rc, относящих объект x к каждому из классов:
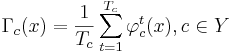
- относит объект x к тому классу, за который подана наибольшая доля голосов:
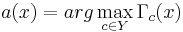
- если максимум достигается одновременно на нескольких классах, выбирается тот,
- подсчитывает долю правил в наборах Rc, относящих объект x к каждому из классов:
для которого цена ошибки меньше.
- Алгоритм взвешенного голосования
- Каждому правилу приписывается вес
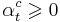
- при голосовании берётся взвешенная сумма голосов:
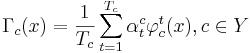
- веса принято нормировать на единицу:
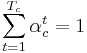
- Каждому правилу
При построении алгоритмов взвешенного голосования правил возникает четыре основных вопроса:
- Как построить много правил по одной и той же выборке?
- Как избежать повторов и построения почти одинаковых правил?
- Как избежать появления непокрытых объектов и обеспечить равномерное покрытие всей выборки правилами?
- Как определять веса правил при взвешенном голосовании?
Алгоритм Кора
- Дано
- множество элементарных предикатов Β
- обучающая выборка X
- Хотим получить
- набор конъюктивных закономерностей (т.е. множество конъюнкций элементарных предикатов Β, которые являлись бы закономерностями для нашей обучающей выборки X) ранга не более чем K (как правило берется число 3)
- доля ошибок
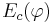 (см. предыдущий билет) для каждой из полученных конъюнкций не должна превышать Emax
(см. предыдущий билет) для каждой из полученных конъюнкций не должна превышать Emax
- доля позитивных объектов
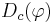 для каждой из полученных конъюнкций должна быть не меньше Dmin
для каждой из полученных конъюнкций должна быть не меньше Dmin
- Реализация
- перебираем все возможные конъюнкции ранга от 1 до K методом поиска в глубину:
- в процессе перебора:
- конъюнкция перестает наращиваться (и отбрасывается), если она выделяет слишком мало объектов своего класса, т.е.
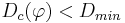
- конъюнкция перестает наращиваться (и запоминается), если она уже удовлетворяет критериям отбора, т.е.
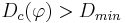 и
и 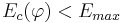
- конъюнкция перестает наращиваться (и отбрасывается), если она выделяет слишком мало объектов своего класса, т.е.
- Достоинства алгоритма
- Короткие конъюнкции легко интерпретируются в терминах предметной области. Алгоритм способен не только классифицировать объекты, но и объяснять свои решения на языке, понятном специалистам.
- При малых K (не больше 3) алгоритм очень эффективен
- Если короткие информативные конъюнкции существуют, они обязательно бу
дут найдены, так как алгоритм осуществляет полный перебор.
- Недостатки алгоритма
- При неудачном выборе множества предикатов B коротких информативных конъюнкций может просто не существовать. В то же время, увеличение числа K приводит к экспоненциальному падению эффективности.
- Алгоритм не стремится обеспечивать равномерность покрытия объектов. Это отрицательно сказывается на обобщающей способности (вероятности ошибки) алгоритма.
Пример применения данного алгоритма - motp.pdf, страница 5
Тесты, представительные наборы, проблемы перебора.
Подмножество столбцов матрцы эталонов Tnmi называется тестом, если в подтаблице, образованной данным подмножеством столбцов, все строки, относящиеся к разным классам, различны.
Каждый столбец соответсвует определенному признаку. Каждая строка - эталонному объекту. Последовательно идущий набор строк - определяет класс.
Тупиковый тест - минимальная подсистема признаков(столбцов), разделяющая эталонные объекты разных классов.
Пример - алгоритм Кора, файл motp.pdf 5 страница. Фактически, характеристики классов строятся при помощи тестов.
Пространства объектов для АВО. Обучающие и контрольные объекты. Метрические описания объектов в АВО.
Алгоритмы вычисления оценок
Дано:
-
![S = \{s_i\},~~ i \in [1, m]](/w/images/math/6/a/e/6ae9cd5ce490ffa2ac31d8aaf958460a.png) -- множество объектов. обучающая выборка
-- множество объектов. обучающая выборка
-
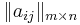 -- совокупность из m объектов, каждый из n свойств
-- совокупность из m объектов, каждый из n свойств
- области определения признаков -- метрические пространства Mt с метриками
![\rho_t:M^2_t \rightarrow \mathbb{R^+},~~ t \in [1, n]](/w/images/math/b/f/b/bfb79b96b10e3494d1b70acfcf4ffc66.png)
-
![K = \{K_i\}~,~~i \in [1, l]](/w/images/math/b/5/2/b52fb2c688c21cf6701c42186edbabee.png) -- можество классов, на которые разделяются объекты
-- можество классов, на которые разделяются объекты
-
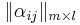 -- информационная матрица (таблица), с указанием того, какой из каждых m объектов каким классам принадлежит
-- информационная матрица (таблица), с указанием того, какой из каждых m объектов каким классам принадлежит
Описание класса -- список объектов из обучающей выборки, которые входят в класс, и список тех, которые не входят
Контрольная выборка -- [?]
Так как пространство признаков не обязательно является числовым, то имеет смысл задавать объект через меры близости к объектам обучающей выборки (метрическое описание объектов) : 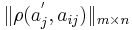 , где
, где
-
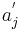 -- j-тый признак описываемого объект
-- j-тый признак описываемого объект
- aij -- j-тый признак i-того объекта базовой выборки S
Опорные множества в АВО. Функции близости. Веса объектов и признаков.
Система опорных множеств -- любое множество, элементы которого - непустые подмножества признаков {1,2...n}. При этом каждый признак должен входить хотя бы в одно множество:
-
![\{\Omega\}_A ~ : ~ \Omega_j = \{u_1, u_2, \dots, u_k\},~ u_k \in [1,n]](/w/images/math/b/c/8/bc867411cf74b986737d0f719bda673f.png) -- совокупность опорных множеств, задающих алгоритм распознавания A
-- совокупность опорных множеств, задающих алгоритм распознавания A
-
![\forall i \in [1,k] ~~ \exists j : i \in \Omega_j](/w/images/math/9/8/b/98bb7331a55658d004b0038808a8675c.png) , каждый признак хотя бы в одном опорном множестве.
, каждый признак хотя бы в одном опорном множестве.
- вместо Ωj можем рассматривать характеристический вектор
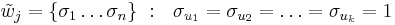 , а остальные координаты равны нулю
, а остальные координаты равны нулю
Примеры опорных множеств:
- совокупность всех непустых подмножеств признаков {1,2...n}. его мощность: 2n − 1
- совокупность из всех подмножеств из k элементов. его мощность:
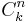
Функция близости 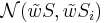 -- задает расстояние между
-- задает расстояние между 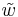 частями распознаваемого объекта S и эталонного объекта Si. В дальнейшем рассматриваются только такие функции,
частями распознаваемого объекта S и эталонного объекта Si. В дальнейшем рассматриваются только такие функции, 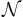 , которые принимают значения 0 или 1
, которые принимают значения 0 или 1
Три вида функции близости:
- введем неотрицательные параметры
![\varepsilon_i > 0 ~,~ i \in [1,n]](/w/images/math/d/a/4/da4b0a3bf47a931a6a408b710cecb80a.png) . Пусть
. Пусть 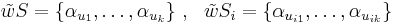 . Тогда
. Тогда ![\mathcal{N}(\tilde w S, \tilde w S_i) =
\begin{cases}
1,~~\rho(\alpha_{u_j}, \alpha_{u_{ij}} \leqslant \varepsilon_{u_j})~~\forall j \in [1,k]\\
0,~~else
\end{cases}](/w/images/math/5/7/2/5727eeb6aa947c1470998a05b2d387d5.png)
- введем дополнительно к п.1 параметра ν такой, что
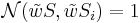 , если не выполнено не больше, чем ν описанных неравенств. при этом имеет смысл брать
, если не выполнено не больше, чем ν описанных неравенств. при этом имеет смысл брать ![0 \leqslant \nu \leqslant \left[\frac{q}{2} - 1\right]](/w/images/math/d/8/6/d86ec798dd54201bf4373dd58a427d8f.png)
- вместо ν определяем ν' так, что , если из k неравенств не выполнены r, причем
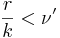
Формулы вычисления оценок. Эвристические обоснования.
Задачи оптимизации АВО. Совместные подсистемы систем неравенств.
Функционалы качества. Сложность моделей алгоритмов и проблема переобучения.
Функционал качества алгоритма. Пусть задана таблица контрольных объектов (множество объектов, на которых мы будет проверять качество работы нашего алгоритма распознавания). Для контрольных объектов мы должны знать, как какому классу свойств относится каждый из объектов (иначе как мы будет проверять корректность работы нашего алгоритма). Подаем контрольные объекты на вход алгоритму. Доля правильных ответов, выданных алгоритмов - это и есть функционал качества.


