ПОД: Ответы старые
Материал из eSyr's wiki.
Информация и её измерения.
Термин "информация" происходит от латинского слова "informatio", что означает сведения, разъяснения, изложение. Несмотря на широкое распространение этого термина, понятие информации является одним из самых дискуссионных в науке. В настоящее время наука пытается найти общие свойства и закономерности, присущие многогранному понятию информация, но пока это понятие во многом остается интуитивным и получает различные смысловые наполнения в различных отраслях человеческой деятельности: в обиходе информацией называют любые данные или сведения, которые кого-либо интересуют. Например, сообщение о каких-либо событиях, о чьей-либо деятельности и т.п. "Информировать" в этом смысле означает "сообщить нечто, неизвестное раньше"; в технике под информацией понимают сообщения, передаваемые в форме знаков или сигналов; в кибернетике под информацией понимает ту часть знаний, которая используется для ориентирования, активного действия, управления, т.е. в целях сохранения, совершенствования, развития системы (Н. Винер).
Клод Шеннон, американский учёный, заложивший основы теории информации — науки, изучающей процессы, связанные с передачей, приёмом, преобразованием и хранением информации, — рассматривает информацию как снятую неопределенность наших знаний о чем-то.
Приведем еще несколько определений: Информация — это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний (Н.В. Макарова); Информация — это отрицание энтропии (Леон Бриллюэн); Информация — это мера сложности структур (Моль); Информация — это отраженное разнообразие (Урсул); Информация — это содержание процесса отражения (Тузов); Информация — это вероятность выбора (Яглом).
Современное научное представление об информации очень точно сформулировал Норберт Винер, "отец" кибернетики. А именно: Информация — это обозначение содержания, полученного из внешнего мира в процессе нашего приспособления к нему и приспособления к нему наших чувств.
Подходы к определению количества информации. Формулы Хартли и Шеннона.
Американский инженер Р. Хартли в 1928 г. процесс получения информации рассматривал как выбор одного сообщения из конечного наперёд заданного множества из N равновероятных сообщений, а количество информации I, содержащееся в выбранном сообщении, определял как двоичный логарифм N. Формула Хартли:
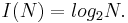
Допустим, нужно угадать одно число из набора чисел от единицы до ста. По формуле Хартли можно вычислить, какое количество информации для этого требуется: I = log2100 > 6,644. Таким образом, сообщение о верно угаданном числе содержит количество информации, приблизительно равное 6,644 единицы информации.
Для задач такого рода американский учёный Клод Шеннон предложил в 1948 г. другую формулу определения количества информации, учитывающую возможную неодинаковую вероятность сообщений в наборе. Формула Шеннона:
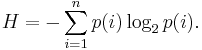
где pi — вероятность того, что именно i-е сообщение выделено в наборе из N сообщений.
Легко заметить, что если вероятности p1,...,pN равны, то каждая из них равна 1 / N, и формула Шеннона превращается в формулу Хартли.
Помимо двух рассмотренных подходов к определению количества информации, существуют и другие. Важно помнить, что любые теоретические результаты применимы лишь к определённому кругу случаев, очерченному первоначальными допущениями.
В качестве единицы информации Клод Шеннон предложил принять один бит (англ. bit — binary digit — двоичная цифра). Бит в теории информации — количество информации, необходимое для различения двух равновероятных сообщений (типа "орел"—"решка", "чет"—"нечет" и т.п.).
В вычислительной технике битом называют наименьшую "порцию" памяти компьютера, необходимую для хранения одного из двух знаков "0" и "1", используемых для внутримашинного представления данных и команд.
Арифметические вычисления до эры ЭВМ.
Эволюционная классификация ЭВМ.
Одна из форм классификации ЭВМ - по "поколениям" связана с эволюцией аппаратного и программного оборудования, причем основным классификационным параметром является технология производства. Классификация рассматривается на примерах из отечественной техники, что дает возможность перечислить хотя бы основных творцов отечественной информационной технологии. История отечественных исследований в данной области пока малоизвестна. Это связано с тем, что работы в данной области длительное время носили закрытый характер. В России (в СССР) начало эры вычислительной техники принято вести от 1946г., когда под руководством Сергея Алексеевича Лебедева закончен проект малой электронной счетной машины (МЭСМ - 50 оп./сек. ОЗУ на 63 команды и 31 константы) - фон Нейманновская универсальная ЭВМ. В 1950/51 гг. она пущена в эксплуатацию. Далее, приводятся некоторые крупные отечественные достижения в области вычислительной техники.
Первое поколение
Первое поколение ЭВМ /1946-1957гг/ использовало в качестве основного элемента электронную лампу. Быстродействие их не превышало 2-3 т. оп./сек; емкость ОЗУ - 2-4 К слов. Это ЭВМ: БЭСМ-1 (В.А. Мельников,1955г.), Минск-1 (И.С. Брук 1952/59 гг.), Урал-4 (Б. И. Рамеев), Стрела (Ю.Я. Базилевский, 1953 г.), М-20 (М.К. Сулим 1860 г.). А.Н. Мямлиным была разработана и несколько лет успешно эксплуатировалась "самая большая в мире ЭВМ этого поколения" - машина Восток. Программирование для этих машин: однозадачный, пакетный режим, машинный язык, ассемблер.
Второе поколение
В ЭВМ второго поколения /1958-1964гг/ элементной базой служили транзисторы. Отечественные: Урал-14,Минск-22,БЭСМ-4,М-220,Мир-2,Наири и БЭСМ-6 (1 млн. оп./сек , 128К), Весна (В.С. Полин, В.К. Левин), М-10 (М.А. Карцев). ПС-2000,ПС-3000, УМШМ, АСВТ, Сетунь. Программирование: мультипрограммный режим, языки высокого уровня, библиотеки подпрограмм.
Третье поколение
Элементная база ЭВМ третьего поколения, /1965-1971гг/ интегральные схемы - логически законченный функциональный блок, выполненный печатным монтажом. Отечественные ЭВМ этого поколения ЭВМ ЕС (Единой Системы):ЕС-1010,ЕС-1020, ЕС-1066 (2 млн. оп./сек , 8192К) и др. Программирование: мультипрограммный, диалоговый режимы, ОС, виртуальная память.
В 1996 г. в России работают 5 тысяч ЕС ЭВМ из 15 т., уставленных а СССР. НИИЦЭВТ на базе комплектующих IBM/390 разработал 23 модели производительностью от 1.5 до 167 Мфлоп (ЕС1270, ЕС1200, аналоги серверов 9672)). IBM предоставляет также лицензионные программные продукты (ОС-390). Используются в Росси для сохранения программного задела прикладных систем (проблема наследия ЕС ЭВМ).
Четвертое поколение
ЭВМ четвертого поколения /1972-1977гг/ базируются на "больших интегральных схемах"(БИС) и "микропроцессорах". Отечественные - проект "Эльбрус", ПК. Программирование: диалоговые режимы, сетевая архитектура, экспертные системы.
Пятое поколение
ЭВМ пятого поколения /начиная с 1978г/ используют "сверхбольшие интегральные схемы" (СБИС). Выполненные по такой технологии процессорные элементы на одном кристалле могут быть основным компонентом различных платформ - серверов: от супер-ЭВМ (вычислительных серверов), до интеллектуальных коммутаторов в файл-серверах.
На этом поколении технологические новации приостанавливаются и в восьмидесятые годы в ряде стран появляются проекты создания новых вычислительных систем на новых архитектурных принципах. Так, в 1982 японские разработчики приступили к проекту "компьютерные системы пятого поколения", ориентируясь на принципы искусственного интеллекта, но в 1991 японское министерство труда и промышленности принимает решение о прекращении программы по компьютерам пятого поколения; вместо этого запланировано приступить к разработке компьютеров шестого поколения на основе нейронных сетей.
В СССР под руководством А.Н. Мямлина в рамках такого проекта велась разработка вычислительной системы, состоящей из специализированных процессоров: процессоров ввода/вывода, вычислительного, символьного, архивного процессоров.
В настоящее время в России создаются мультисистемы на базе зарубежных микропроцессоров: вычислительные кластеры (НИИЦЭВТ), супер-ЭВМ МВС-1000 (В.К. Левин, А.В.Забродин). Под руководством Б.А.Бабаяна проектируется микропроцессор Мерсед-архитектектуры. В.С. Бурцев разрабатывает проект суперЭМВ на принципах потоковых машин.
Эволюция отечественного программного обеспечения непосредственно связана с эволюцией архитектуры ЭВМ, первая Программирующая Программа ПП, Интерпретирующая Система- ИС создавались для М-20 (ИПМ). Для ЭВМ этого семейства были реализованы компиляторы с Алгола: ТА-1 (С.С.Лавров), ТФ-2 (М.Р.Шура-Бура), Альфа(А.П.Ершов).
Для БЭСМ-6 создан ряд операционные системы: от Д-68 до ОС ИПМ (Л.Н. Королев, В.П. Иванников, А.Н. Томилин, В.Ф.Тюрин, Н.Н. Говорун, Э.З. Любимский).
Под руководством С.С.Камынина и Э.З. Любимского был реализован проект Алмо: создание машинно-ориентированного языка и на его базе системы мобильных трансляторов.
В.Ф.Турчин предложил функциональный язык Рефал, системы программирования на базе этого языка используются при создании систем символьной обработки и в исследованиях в области мета вычислений.
Принципы фон Неймановской архитектуры.
В основу построения подавляющего большинства компьютеров положены следующие общие принципы, сформулированные в 1945 г. американским ученым Джоном фон Нейманом.
Принцип программного управления.
Из него следует, что программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности. Выборка программы из памяти осуществляется с помощью счетчика команд. Этот регистр процессора последовательно увеличивает хранимый в нем адрес очередной команды на длину команды. А так как команды программы расположены в памяти друг за другом, то тем самым организуется выборка цепочки команд из последовательно расположенных ячеек памяти. Если же нужно после выполнения команды перейти не к следующей, а к какой-то другой, используются команды условного или безусловного переходов, которые заносят в счетчик команд номер ячейки памяти, содержащей следующую команду. Выборка команд из памяти прекращается после достижения и выполнения команды “стоп”. Таким образом, процессор исполняет программу автоматически, без вмешательства человека.
Принцип однородности памяти.
Программы и данные хранятся в одной и той же памяти. Поэтому компьютер не различает, что хранится в данной ячейке памяти — число, текст или команда. Над командами можно выполнять такие же действия, как и над данными. Это открывает целый ряд возможностей. Например, программа в процессе своего выполнения также может подвергаться переработке, что позволяет задавать в самой программе правила получения некоторых ее частей (так в программе организуется выполнение циклов и подпрограмм). Более того, команды одной программы могут быть получены как результаты исполнения другой программы. На этом принципе основаны методы трансляции — перевода текста программы с языка программирования высокого уровня на язык конкретной машины.
Принцип адресности.
Структурно основная память состоит из перенумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка. Отсюда следует возможность давать имена областям памяти, так, чтобы к запомненным в них значениям можно было впоследствии обращаться или менять их в процессе выполнения программ с использованием присвоенных имен. Компьютеры, построенные на этих принципах, относятся к типу фон-неймановских. Но существуют компьютеры, принципиально отличающиеся от фон-неймановских. Для них, например, может не выполняться принцип программного управления, т.е. они могут работать без “счетчика команд”, указывающего текущую выполняемую команду программы. Для обращения к какой-либо переменной, хранящейся в памяти, этим компьютерам не обязательно давать ей имя. Такие компьютеры называются не-фон-неймановскими.
Виды запоминающих устройств.
Система построена из разнообразных элементов, поэтому для того, чтобы она правильно функционировала, применяются специальные средства, сглаживающие дисбаланс (историческое решение – регистры общего назначения), достигается минимум реальной частоты обращения к памяти - расслоение памяти (это параллельность передачи данных и передача управления). Считывание в память фрагментов данных – организация ассоциативной памяти – КЭШа – сверхоперативной памяти, которая аккумулирует наиболее частые команды и минимизирует обращения к оперативной памяти. Также широко используется аппарат прерываний- средство, аппаратно-ориентированное на своевременную обработку поступающей информации, осуществляющее реакцию на ошибки.
Система внешних запоминающих устройств (ВЗУ) компьютера очень широка, она включает в себя типовой набор внешних устройств Традиционно это:
- внешние запоминающие устройства, предназначенные для организации хранения данных и программ;
- устр-ва ввода и отображения, предназначенные для ввода извне данных и программ и отображения этой инф-ции;
- устр-ва приема данных, предназначенные для получения данных от других компьютеров и извне.
- Обмен данными:
- записями фиксированного размера – блоками
- записями произвольного размера
- Доступ к данным:
- операции чтения и записи (жесткий диск, CDRW).
- только операции чтения (CDROM, DVDROM, …).
По доступу к данным различают устройства:
Последовательного доступа:
В устройствах последовательного доступа для чтения i-ого блока памяти необходимо пройти по первым i-1 блокам. (Пример: пульт дистанционного управления ТВ, кнопки «канал+» и «канал-» или бытовые кассетные магнитофоны - ВЗУ большинства бытовых компьютеров 80-х годов). Устройства последовательного доступа менее эффективны чем устройства прямого доступа.
- Магнитная лента. Это тип ВЗУ широко известный всем пользователям бытовых компьютеров. Его принцип основывается на записи/чтении информации на магнитной ленте. При этом перед началом и окончанием очередной записи на ленту заносится специальный признак - маркер начала, соответственно, конца. Головка проходит на нужный номер цилиндра и не более чем зза 1 оборот находит нужный сектор.
Прямого доступа:
В устройствах прямого доступа для того, чтобы прочесть i-ый блок данных, не нужно читать первые i-1 блоков данных. (Пример: пульт дистанционного управления Вашего телевизора, кнопки - каналы; для того, чтобы посмотреть i-ый канал не нужно «перещелкивать» первые i-1).
- Магнитные диски. Конструкция ВЗУ данного типа состоит в том, что имеется несколько дисков (компьютерный жаргон - «блины»), обладающих возможностью с помощью эффекта перемагничивания хранить информацию, размещенных на оси, которые вращаются с некоторой постоянной скоростью. Каждый такой диск имеет одну или две поверхности, покрытые слоем, позволяющим записывать информацию
- Магнитный барабан.металлический цилиндр большой массы, вращающийся вокруг своей оси. Роль большой массы - поддержание стабильной скорости вращения. Поверхность этого цилиндра покрыта магнитным слоем, позволяющим хранить, читать и записывать информацию. Поверхность барабана разделена на n равных частей (в виде колец), которые называются треками (track). Над барабаном расположен блок неподвижных головок так, что над каждым треком расположена одна и только одна головка. (Головок, соответственно, тоже n штук). Головки способны считывать и записывать информацию с барабана. Каждый трек разделен на равные сектора. В каждый момент времени в устройстве может работать только одна головка. Запись информации происходит по трекам барабана, начиная с определенного сектора. При заказе на обмен поступают следующие параметры: № трека, № сектора, объем информации.
- • Магнито-электронные ВЗУ прямого доступа (память на магнитных доменах).В конструкции этого устройства опять таки используется барабан, но на этот раз он неподвижен. Барабан опять таки разделен на треки и над каждым треком имеется своя головка. За счет некоторых магнитно-электрических эффектов происходит перемещение по треку цепочки доменов. При этом каждый домен однозначно ориентирован, то есть он бежит стороной, с зарядом «+», либо стороной, заряженной «-». Так кодируется ноль и единица. Эта память очень быстродейственна, т.к. в ней нет «механики». Память на магнитных доменах очень дорога и используется в большинстве случаев в военной и космической областях.
Иерархия памяти
Выглядит следующим образом:

Адресация ОЗУ.
ОЗУ - устройство, предназначенное для хранения оперативной информации. В ОЗУ размещается исполняемая в данный момент программа и используемые ею данные. ОЗУ состоит из ячеек памяти, каждая из которых содержит поле машинного слова и поле служебной информации.
Машинное слово – поле программно изменяемой информации, в машинном слове могут располагаться машинные команды (или части машинных команд) или данные, с которыми может оперировать программа. Машинное слово имеет фиксированный для данной ЭВМ размер (обычно размер машинного слова – это количество двоичных разрядов, размещаемых в машинном слове).
Служебная информация (иногда ТЭГ) – поле ячейки памяти, в котором схемами контроля процессора и ОЗУ автоматически размещается информация, необходимая для осуществления контроля за целостностью и корректностью использования данных, размещаемых в машинном слове.
 Использование содержимого поля служебной информации
Использование содержимого поля служебной информации
- контроль за целостностью данных.: (при записи машинного слова подсчет числа единиц в коде машинного слова и дополнение до четного или нечетного в контрольном разряде), при чтении контроль соответствия;
Пример контроля за целостностью данных по четности.

- контроль доступа к командам/данным (обеспечение блокировки передачи управления на область данных программы или несанкционированной записи в область команд);
- контроль доступа к машинным типам данных – осуществление контроля за соответствием машинной команды и типа ее операндов;
Конкретная структура, а также наличие поля служебной информации зависит от конкретной ЭВМ.
В ОЗУ все ячейки памяти имеют уникальные имена, имя - адрес ячейки памяти. Обычно адрес – это порядковый номер ячейки памяти (нумерация ячеек памяти возможна как подряд идущими номерами, так и номерами, кратными некоторому значению). Доступ к содержимому машинного слова осуществляется посредством использования адреса. Производительность оперативной памяти – скорость доступа процессора к данным, размещенным в ОЗУ.
- время доступа (access time- taccess) – время между запросом на чтение слова из оперативной памяти и получением содержимого этого слова.
- длительность цикла памяти (cycle time – tcycle) – минимальное время между началом текущего и последующего обращения к памяти.
Обычно скорость доступа к данным ОЗУ существенно ниже скорости обработки информации в ЦП. (tcycle>>taccess). Необходимо, чтобы итоговая скорость выполнения команды процессором как можно меньше зависела от скорости доступа к коду команды и к используемым в ней операндам из памяти. Это составляет проблему, которая системным образом решается на уровне архитектуры ЭВМ.
Расслоение оперативной памяти.
Расслоение ОЗУ – один из аппаратных путей решения проблемы дисбаланса в скорости доступа к данным, размещенным в ОЗУ и производительностью ЦП. Суть расслоения ОЗУ состоит в следующем. Все ОЗУ состоит из k блоков, каждый из которых может работать независимо. Ячейки памяти распределены между блоками таким образом, что у любой ячейки ее соседи размещаются в соседних блоках. Возможность предварительной буферизации при чтении команд/данных. Оптимизация при записи в ОЗУ больших объемов данных.

При конвейерном доступе при М-кратном расслоении и регулярной выборке доступ к памяти возможен в интервале 1/М цикла памяти. Но возможны конфликты по доступу, если шаг регулярной выборки коррелируется с числом банков памяти.
Ассоциативная память.
Оперативную память (ОП) можно представить в виде двумерной таблицы, строки которой хранят в двоичном коде команды и данные. Обращения за содержимом строки производится заданием номера (адреса) нужной строки. При записи, кроме адреса строки указывается регистр, содержимое которого следует записать в эту строку. Запись занимает больше времени, чем чтение. Пусть в памяти из трех строк хранятся номера телефонов.
| 1924021 |
| 9448304 |
| 3336167 |
Для получения номера телефона второго абонента следует обратиться: load (2) и получить в регистре ответа R = 9448304. Такой вид памяти, при котором необходимая информация определяется номером строки памяти, называется адресной. Другой вид оперативной памяти – ассоциативной можно рассматривать также как двумерную таблицу, но у каждой строки которой есть дополнительное поле, поле ключа.
Например:
| Ключ | Содержимое |
|---|---|
| Иванов | 1924021 |
| Петров | 9448304 |
| Сидоров | 3336167 |
После обращение к ассоциативной памяти с запросом : load (Петров) для данного примера получим ответ: R = 9448304. Здесь задание координаты строки памяти производится не по адресу, а по ключу. Но при состоянии ассоциативной памяти:
| Ключ | Содержимое |
|---|---|
| 1 | 1924021 |
| 2 | 9448304 |
| 3 | 3336167 |
можно получить номер телефона из второй строки запросом: load (2). Таким образом на ассоциативной памяти можно моделировать работу адресной. Ассоциативная память имеет очевидное преимущества перед адресной, однако, у нее есть большой недостаток - ее аппаратная реализация невозможна для памяти большого объема.
ВОПРОС: Предложите схему реализации модели ассоциативной памяти при помощи адресной.
Ответ: Область памяти делим ровно пополам. Первая половина заполняется ключами, вторая соответствующими ключам значениями. Когда найден ключ, известен его адрес как смещение относительно начала памяти. Тогда адрес содержимого по ключу – это смещение + размер области ключей, то есть адрес ячейки из второй половины памяти, которая соответствует ключу.
Виртуальная память.
Внутри программы к моменту образования исполняемого модуля используется модель организации адресного пространства программы (эта модель, в общем случае не связана с теми ресурсами ОЗУ, которые предполагается использовать позднее). Для простоты будем считать, что данная модель представляет собой непрерывный фрагмент адресного пространства в пределах которого размещены данные и команды программы. Будем называть подобную организацию адресации в программе программной адресацией или логической/виртуальной адресацией.
Итак, повторяем, на уровне исполняемого кода имеется программа в машинных кодах, использующая адреса данных и команд. Эти адреса в общем случае не являются адресами конкретных физических ячеек памяти, в которых размещены эти данные, более того, в последствии мы увидим, что виртуальным (или программным) адресам могут ставиться в соответствие произвольные физические адреса памяти. То есть при реальном исполнении программы далеко не всегда виртуальная адресация, используемая в программе совпадает с физической адресацией, используемой ЦП при выполнении данной программы.
Базирование адресов.
Элементарное программно-аппаратное решение – использование возможности базирования адресов.
Суть его состоит в следующем: пусть имеется исполняемый программный модуль. Виртуальное адресное пространство этого модуля лежит в диапазоне [0, Aкон]. В ЭВМ выделяется специальный регистр базирования Rбаз., который содержит физический адрес начала области памяти, в которой будет размещен код данного исполняемого модуля. При этом исполняемые адреса, используемые в модуле будут автоматически преобразовываться в адреса физического размещения данных путем их сложения с регистром Rбаз.. Таким образом код используемого модуля может. Эта схема является элементарным решением организации простейшего аппарата виртуальной памяти. Аппарат виртуальной памяти – аппаратные средства компьютера, обеспечивающие преобразование (установление соответствия) программных (виртуальных) адресов, используемых в программе адресам физической памяти в которой размещена программа при выполнении.
Пусть имеется вычислительная система, функционирующая в мультипрограммном режиме. То есть одновременно в системе обрабатываются несколько программ/процессов. Один из них занимает ресурсы ЦП. Другие ждут завершения операций обмена, третьи – готовы к исполнению и ожидают предоставления ресурсов ЦП. При этом происходит завершение выполнявшихся процессов и ввод новых, это приводит к возникновению проблемы фрагментации ОЗУ. Суть ее следующая. При размещении новых программ/процессов в ОЗУ ЭВМ (для их мультипрограммной обработки) образуются свободные фрагменты ОЗУ между программами/процессами. Суммарный объем свободных фрагментов может быть достаточно большим, но, в то же время, размер самого большого свободного фрагмента недостаточно для размещения в нем новой программы/процесса. В этой ситуации возможна деградация системы – в системе имеются незанятые ресурсы ОЗУ, но они не могут быть использованы. Путь решения этой проблемы – использование более развитых механизмов организации ОЗУ и виртуальной памяти, позволяющие отображать виртуальное адресное пространство программы/процесса не в одну непрерывную область физической памяти, а в некоторую совокупность областей.
Страничная организация памяти
Страничная организация памяти предполагает разделение всего пространства ОЗУ на блоки одинакового размера – страницы. Обычно размер страницы равен 2k. В этом случае адрес, используемый в данной ЭВМ, будет иметь следующую структуру:
Модельная (упрощенная) схема организации функционирования страничной памяти ЭВМ следующая: Пусть одна система команд ЭВМ позволяет адресовать и использовать m страниц размером 2k каждая. То есть виртуальное адресное пространство программы/процесса может использовать для адресации команд и данных до m страниц.
Физическое адресное пространство – оперативная память, подключенная к данному компьютеру. Физическое адресное пространство, в общем случае может иметь произвольное число физических страниц (их может быть больше m, а может быть и меньше). Соответственно структура исполнительного физического адреса будет отличаться от структуры исполнительного виртуального адреса за счет размера поля ”номер страницы”.
В виртуальном адресе размер поля определяется максимальным числом виртуальных страниц – m.
В физическом адресе – максимально возможным количеством физических страниц, которые могут быть подключены к данной ЭВМ (это также фиксированная аппаратная характеристика ЭВМ).
В ЦП ЭВМ имеется аппаратная таблица страниц (иногда таблица приписки) следующей структуры:
Таблица содержит m строк. Содержимое таблицы определяет соответствие виртуальной памяти физической для выполняющейся в данный момент программы/процесса. Соответствие определяется следующим образом: i-я строка таблицы соответствует i-й виртуальной странице. Содержимое строки αi определяет, чему соответствует i-я виртуальная страница программы/процесса. Если αi ≥ 0, то это означает, что αi есть номер физической страницы, которая соответствует виртуальной странице программы/процесса. Если αi= -1, то это означает, что для i-й виртуальной страницы нет соответствия физической странице ОЗУ (обработка этой ситуации ниже).
Итак, рассмотрим последовательность действий при использовании аппарата виртуальной страничной памяти.
- При выполнении очередной команды схемы управления ЦП вычисляют некоторый адрес операнда (операндов) Aисп. Это виртуальный исполнительный адрес.
- Из Aисп. Выделяются значимые поля номер страницы (номер виртуальной страницы). По этому значению происходит индексация и доступ к соответствующей строке таблицы страниц.
- Если значение строки ≥ 0, то происходит замена содержимого поля номер страницы на соответствующее значение строки таблицы, таким образом, получается физический адрес. И далее ЦП осуществляет работу с физическим адресом. Если значение строки таблицы равно –1 это означает, что полученный виртуальный адрес не размещен в ОЗУ. Причины такой ситуации? Их две. Первая – данная виртуальная страница отсутствует в перечне станиц, доступных для программы/процесса, то есть имеет место попытка обращения в “ чужую”, не легитимную память. Вторая ситуация, когда операционная система в целях оптимизации использования ОЗУ, откачала некоторые страницы программы/процесса в ВЗУ(свопинг).


